询问与否:学习获取人类反馈
摘要
开发能在分类任务中与人类性能互补的决策支持系统,仍是一项尚未解决的挑战。“学习委托”(Learning to Defer,LtD)是一种广泛应用的方法,它允许机器学习(ML)模型将复杂案例交由人类专家处理。然而,LtD 将人类与机器学习模型视为相互排斥的决策者,仅将专家的作用局限于提供预测结果,这一局限极大地限制了专家的贡献。为解决这一问题,本文提出 “学习询问”(Learning to Ask,LtA)这一全新框架,该框架不仅能确定何时需要纳入专家输入,还能明确如何将专家输入融入机器学习模型。
LtA 基于双组件架构:一个标准机器学习模型,以及一个利用额外人类专家反馈训练的增强模型(enriched model),同时还包含一套用于确定何时查询增强模型的理论最优策略。本文提供了两种 LtA 的实际实现方式:一种是序贯方法(sequential approach),分阶段训练模型;另一种是联合方法(joint approach),对模型进行同步优化。针对联合方法,本文设计了具有可实现一致性(realisable-consistency)保障的替代损失函数(surrogate losses)。在合成数据和真实专家数据上的实验表明,LtA 为实现高效的人类 – 人工智能协作提供了更灵活、更强大的基础。
1 引言
过去几年,机器学习领域的进步推动了各类任务性能的大幅提升,使得模型在特定领域的能力甚至超越了人类的理解与表现 [11,13,38,45,35,24,32]。然而,在许多实际应用场景中,由于存在系统性偏差 [25]、问责缺失 [14] 以及泛化能力有限 [17] 等问题,完全自动化并不可取。因此,如何构建融合人类专家反馈、实现性能互补的人类 – 人工智能协作框架,逐渐成为研究热点 [3]。
以急诊室分诊场景为例,医疗人员需要对患者进行评估并确定优先救治顺序。尽管数据驱动的决策支持系统已展现出出色的性能 [9,28],但与决策者(医疗人员)相比,这些系统获取的患者信息往往更为有限。事实上,在某些任务中,有研究表明专业医生能够利用决策支持系统无法获取的信息(如患者的口述病史)来做出决策 [1]。
例如,有研究发现,医生在诊断急性上消化道出血(AGIB)时,会考虑抗凝药物使用情况等额外因素,而这些因素并未包含在用于评估 AGIB 风险的标准格拉斯哥 – 布拉奇福德评分(Glasgow-Blatchford Score)[16] 中(该评分包含 9 个变量)。因此,医生的决策所产生的入院 / 出院判断影响,超出了仅基于这些变量训练的算法所能覆盖的范围 [1]。
由此可见,融入专家反馈能够提升模型的准确诊断能力,尤其是在需要临床判断的场景中。
(左图)在传统 LtD 任务中,给定样本x∈X,通过选择策略s(x)决定将最终预测任务交由人类专家还是机器学习预测器完成。然而,专家与预测器可能分别掌握相互独立的有效特征(例如,复杂的医疗信号与患者的口述病史)。(右图)本文提出的 LtA 框架(第 4 节)则聚焦于两个核心问题:何时需要获取人类输入,以及如何将这些互补信息h∈H融入增强预测器g:X×H→Y。
“性能互补” 的概念已成为人机交互(HCI)[15] 以及近年来混合决策(Hybrid Decision Making,HDM)领域的重点研究方向。其核心动因在于,人类推理与机器学习系统存在本质差异,二者在任务的不同子集上各有所长。然而,如何确定人类与机器学习系统何时以及如何实现有效互补,仍是一个亟待解决的挑战 [36]。这一问题在高风险场景中尤为关键 —— 在这类场景中,系统必须能够可靠地判断是依赖人类专家还是机器预测,以实现整体性能最大化 [39]。
在各类决策框架中,“学习委托”(LtD)[19] 近年来备受关注。LtD 在标准监督学习的基础上引入了委托机制,允许机器学习模型自主选择是进行预测,还是将决策委托给人类专家 [33]。该框架为构建更具适应性的协作系统提供了可能,尤其在人类专业知识能够补充算法预测的场景中效果显著。
然而,若以 “性能互补” 为目标,LtA 方法仍存在两大关键缺陷:
- 反馈形式局限:LtD 要求人类专家提供特定于任务的预测结果,却忽略了其他形式的专家反馈(如概念标注、部分特征描述等),而这些反馈同样能用于提升最终预测性能。
- 协作模式单一:LtD 将专家与机器视为独立的决策者,未能利用二者间潜在的协同效应,往往会导致系统性欠拟合 [18],进而浪费宝贵的信息资源。
为此,本文提出全新的 “学习询问”(LtA)框架。该框架在保留 LtD 灵活性的同时,解决了现有方法的核心局限。与 LtD 优化 “何时将完整决策委托给机器或人类” 不同,LtA 聚焦于 “在预测过程中何时需要获取专家反馈”。这一目标通过双组件架构实现:一个标准分类器,以及一个在需要时能融入专家输入的增强模型(见图 1)。该设计不仅能捕捉人类与机器之间的潜在互补性,还能实现协同协作,让二者同时为预测任务做出贡献。
本文贡献
- 理论分析:证明存在(且可能大量存在)这样的数据分布 —— 在这些分布下,LtD 方法具有理论上的次优性,即单纯将决策委托给专家或机器无法提升期望准确率(第 3 节)。
- 框架构建:提出用于训练 “能判断何时获取专家反馈” 的机器学习模型的形式化框架,该框架支持一般形式的额外输入,并推导了 LtA 的理论最优选择策略(定理 1)。
- 方法实现:提出两种 LtA 的学习策略:
- (i)序贯模型(sequential model):先训练增强模型,再利用成熟的 LtD 损失函数训练标准模型与选择策略;
- (ii)联合模型(joint model):设计全新的具有可实现一致性的替代损失函数,支持 LtA 框架下的联合优化(定理 2)。
- 实验验证:在合成数据与真实分类任务上对所提策略进行实证验证(第 5 节),结果表明,当提供更丰富的反馈时,LtA 的性能优于 LtD。
本文已将实验所用源代码及原始结果开源,可通过以下链接获取:https://github.com/andrepugni/LearningToAsk。
2 研究背景
设X为特征空间,Y为目标空间。在 LtD 中,目标是学习一个模型f:X→Y(用于预测目标变量)和一个选择器s:X→{0,1}(用于决定何时将决策委托给人类专家)。预测器与选择策略的假设空间记为F×S。本文将人类专家视为另一个固定的预测器f′∈F′。
给定X×Y×F′上的未知概率分布P′,LtD 的目标是最小化以下目标函数:<sup>[2]</sup>
<sup>[2]</sup> 为简化符号,用Ev表示对服从某分布PV的随机变量V求期望,例如E(x,y,f′)[⋅]=E(x,y,f′)∼P′[⋅]。
(f,s)∈F×SminE(x,y,f′)[L0−1def(f(x),s(x),f′,y)](1)
其中,L0−1def(f(x),s(x),f′,y)=I{f(x)=y}I{s(x)=0}+(αI{f′=y}+δ)I{s(x)=1} 是委托 0-1 损失函数。α∈[0,1]为归一化因子,δ∈[0,1]为委托成本(用于衡量查询人类专家的代价)。除非特别说明,本文默认α=1且δ=0,这与大多数 LtD 相关文献的设定一致 [26,27,22]。
式(1)中的损失函数通常难以直接优化,因此许多研究采用替代损失函数(surrogate losses)。形式上,设EL(q)表示假设q∈Q在损失L下的泛化误差,即EL(q)=Ex,y,f′[L(q(x),y,f′)];EL∗表示最优泛化误差,即EL∗=infq∈QEx,y,f′[L(q(x),y,f′)]。在 LtD 场景中,假设空间Q由所有预测器f与选择策略s的组合构成。
替代损失函数的一个理想性质是贝叶斯一致性(Bayes-consistency):在渐近情况下,对整个假设类(如 LtD 中的f和s)最小化替代损失Lsurr,能够保证对同一假设类最小化原始的难优化损失Lorig[23],即:
n→∞limELsurr(qn)−ELsurr∗=0⟹n→∞limELorig(qn)−ELorig∗=0(2)
其中,qn是从n个样本中学习得到的假设序列。
然而,式(2)所定义的一致性是基于所有可测函数族的,在实际场景中(学习通常局限于有限假设类)并不实用。为解决这一问题,替代损失函数需满足可实现Q一致性(realisable Q-consistency):若存在假设q∗∈Q使得ELorig(q∗)=0,且q′=argminq∈QELsurr(q),则ELsurr(q′)=0。通俗地说,若 “完美假设”(如 LtD 中的(f,s)∗)存在于给定假设类中,那么最小化替代损失将能渐近地找到该完美假设 [23]。
例如,Madras 等人 [19] 提出的一种适用于 LtD 的可实现一致性替代损失,用交叉熵项的组合替代了不连续的委托损失:
(1−s(x))⋅ℓCE(f(x),y)+s(x)⋅ℓCE(f′,y)(3)
其中,ℓCE表示标准交叉熵损失。
更多相关研究
LtD 是混合决策的一种典型形式,其核心是让自动化预测器学习何时将预测任务委托给人类专家。由于直接优化式(1)存在困难,已有研究提出了具有一致性的替代损失函数,用于同时学习选择函数与预测器 [26,29,5,40,27,4,18,43]。近年来,相关研究进一步拓展了 LtD 的应用场景,包括多人类专家协作 [41,20]、机器学习模型已固定且无需联合训练 [20],以及评估引入 LtD 方法的因果效应 [30] 等。
本文工作与 Wilder 等人 [44] 和 Charusaie 等人 [6] 的研究密切相关。这两项研究同样考虑将人类专家的反馈作为额外输入融入最终预测任务,但与本文存在两点关键差异:(i)它们将人类反馈局限于专家的预测结果;(ii)未明确考虑 “预算感知的专家反馈查询”(这是实际应用中的核心需求)。此外,这两项研究缺乏对学习方法的形式化分析,而本文为最优选择策略(定理 1)和可实现一致性(定理 2)提供了全新的理论结果。
其他人类 – 人工智能框架
已有大量研究致力于改进人类 – 人工智能协作。例如,近期研究聚焦于如何利用保形预测(conformal prediction)[34] 提升人类 – 人工智能团队的联合决策能力 [37,10]。Alur 等人 [1] 提出了一个统计框架,用于判断人类专家是否能为特定预测任务带来价值,并提供了数据驱动的验证流程。在 Alur 等人 [2] 的研究中,作者提出了识别机器学习模型局限性的方法,并基于观察到的互补性(事后分析)评估人类专家反馈是否能提升模型性能。
本文与上述研究的核心差异在于:本文聚焦于 “学习构建能判断何时获取专家反馈的模型”,而 Alur 等人 [2] 的研究仅关注 “事后验证专家反馈是否能提升预测性能”,并未涉及任何学习过程。
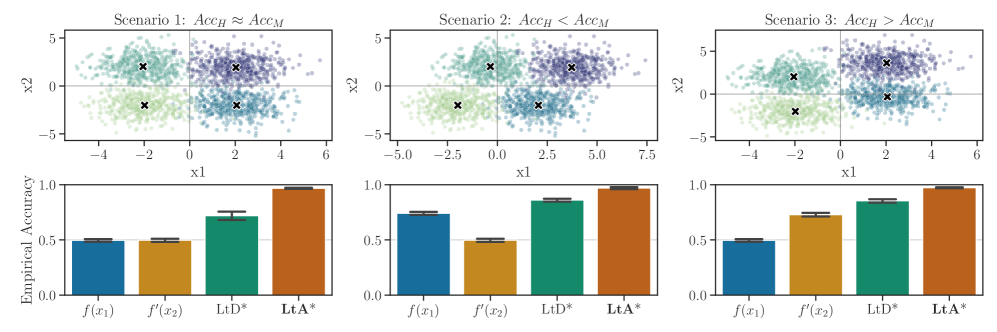
(上图)合成分类任务包含两个二元特征x1,x2∈{0,1}和四个类别Y∈{0,1,2,3}。通过调整每个特征的信息性(即特征对预测真实标签的区分能力),构建三种场景,分别对应专家准确率(AccH)与机器准确率(AccM)在测试集上的不同表现。(下图)在每种场景中,仅基于单一特征的机器预测器f(x1)(对应图例)和人类专家预测器f′(x2)(对应图例)均无法单独完美预测Y。即使是 “最优委托策略” LtD*(对应图例,在可能的情况下始终选择正确预测),也会受限于单一特征的信息不足。只有融合两种信号的策略 LtA*(对应图例)才能实现完美分类。每个场景的结果均报告五次实验的标准差。
3 论 “学习委托”(LtD)的次优性
上一节已说明,LtD 可通过实用且具有一致性的替代损失函数,在有限样本保证下最小化式(1)的目标函数。然而,在某些数据分布下,LtD 的最优委托策略可能具有次优性。
考虑一个简化的分类任务:离散随机变量X=(x1,x2)(其中x1,x2∈{0,1}),标签变量Y∈{0,1,2,3}。每个标签y∈Y均与x1和x2的唯一组合存在确定性对应关系。设x1为自动化决策支持系统使用的特征(如由生命体征构成的复杂函数),x2为需通过人类专家额外信息处理才能获取的高成本特征(如患者的口述病史)。
机器预测f(x1)仅基于x1,专家预测f′(x2)仅基于x2,且二者均为贝叶斯最优预测器。若机器学习模型仅能观测x1,则:
- 当x1=0时,P(f(x1)∣x1=0)=21(f(x1)∈{0,2});
- 当x1=1时,P(f(x1)∣x1=1)=21(f(x1)∈{1,3})。
反之,对于专家预测:
- 当x2=0时,P(f′(x2)∣x2=0)=21(f′(x2)∈{0,1});
- 当x2=1时,P(f′(x2)∣x2=1)=21(f′(x2)∈{2,3})。
给定样本x,采用策略s(x1)的 LtD 系统的期望准确率是专家准确率与机器准确率的凸组合:
Ey[s(x1)I{f(x1)=y}+(1−s(x1))I{f′(x2)=y}](4)
在该设定下,任何选择器s(⋅)的期望准确率都无法超过21。这是因为 LtD 系统未能利用专家与机器学习模型各自掌握的互补信息(如本例中的x2)。
若换用一种 “将专家输入融入分类器” 的替代模型(例如,专家将收集到的特征x2提供给一个统一模型),设该融合系统的预测为g(x1,x2)。由于能同时获取x1和x2,该模型可完美预测真实标签Y,实现最优准确率。此时,只要s(x1)>0,使用g(x1,x2)的增强系统的准确率就会严格高于21。
图 2 通过实证展示了在三种不同场景(基于预测器与人类专家的基础准确率,由特征信息性决定)下,“最优 LtD” 的次优性。完整推导与实验设置详见附录 A.1。
然而,在实际应用中,为每个样本获取在线专家反馈(无论是预测结果还是额外特征)都可能需要高昂成本,且并非总能实现。<sup>[3]</sup>
<sup>[3]</sup> 例如,在急诊室(ED)分诊决策支持系统中,急诊医生常面临频繁的工作中断与高强度工作负荷 [7]。因此,自动化系统必须谨慎优化 “何时请求专家提供额外反馈”。
为此,下一节将聚焦于 “在预算约束下刻画最优选择策略”,平衡 “获取专家额外反馈的需求” 与 “最大化系统准确率的目标”。
4 “学习询问”(LtA)
本文旨在扩展式(1),将f′明确建模为一个不同的函数g:X×H→Y,其中H⊆Rd(d>0)为专家反馈空间。直观上,H可视为除X之外的高成本特征集合,包括但不限于:
- 专家对任务的预测结果(与 LtD 一致);
- 专家的不确定性预测(如医生对诊断结果的置信度);
- 额外特征(如医生安排的额外检查);
- 非结构化标注(如完整的医疗报告)。
本文将g称为增强预测器(enriched predictor),将f称为标准预测器(standard predictor)。值得注意的是,LtD 是 LtA 的一种特殊情况 —— 当H=Y且g(x,h)=h时,LtA 退化为 LtD。
定义L0−1ask损失如下:
L0−1ask(f(x),g(x,h),s(x),y)=I{f(x)=y}I{s(x)=0}+I{g(x,h)=y}I{s(x)=1}(5)
其中,s(x):X→{0,1}为选择函数,用于决定由哪个模型提供最终预测:当s(x)=0时,由标准模型预测;当s(x)=1时,由增强模型预测。
由于该损失同样难以直接优化,本文采用如下定义的替代损失Lask:
Lask(f(x),g(x,h),s(x),y)=ℓf(f(x),y)(1−s(x))+ℓg(g(x,h),y)s(x)(6)
其中,ℓf是标准预测器的替代损失函数,ℓg是增强模型g的替代损失函数(二者可不同)。
给定X×Y×H上的分布P,LtA 的目标函数为:
f,g,s∈F×G×SminE(x,y,h)[Lask(f(x),g(x,h),s(x),y)](7)
为避免过度依赖专家,本文在式(7)中加入预算约束β:要求标准模型f覆盖(1−β)%的样本,而查询专家的次数不超过β%。<sup>[4]</sup>
<sup>[4]</sup> 在 “弃权学习”(abstention learning)文献中,用预算约束β或参数α、δ建模专家成本的方法已有悠久历史。详见 Franc 等人 [12]、Ruggieri 与 Pugnana [33] 的相关讨论。
因此,优化问题变为:
f,g,s∈F×G×SminE(x,h,y)[Lask(f(x),g(x,h),s(x),y)]s.t.Ex[s(x)]≤β(8)
与 Okati 等人 [29] 的研究类似,给定任意预测器f∈F和增强预测器g∈G,可将最优选择函数s∗∈S刻画为如下定理:
定理 1
设f∈F为标准预测器,g∈G为固定增强预测器。定义ΔE(ℓf,ℓg)=Ey∣x[ℓf(f(x),y)]−Ey,h∣x[ℓg(g(x,h),y)](表示f与g的期望条件风险之差),且假设该差值连续。则式(8)优化问题的最优选择函数s∗可表示为:
s∗(x)={1若ΔE(ℓf,ℓg)>τβ∗0其他情况(9)
其中,τβ∗=infλ{λ≥0:P(Ey∣x[ℓf(f(x),y)]−Ey,h∣x[ℓg(g(x,h),y)]>λ)≤β}。
定理 1 解读:在预算β约束下,最优选择策略为 —— 仅当 “标准预测器的期望损失与增强模型的期望损失之差” 大于该差值的(1−β)分位数时,才查询增强预测器。完整证明详见附录 A.3。
下一节将说明如何通过定制化的替代函数实际学习 LtA 方法,同时证明这些替代函数具有可实现性与一致性。
4.1 如何实际学习 LtA 方法
部署 LtA 方法需学习三个模型:预测器(f)、增强预测器(g)与选择策略(s)。本文提出两种实现方法:LtA – 序贯训练(LtA-Seq,分阶段训练模型)与LtA – 联合训练(LtA-Joint,同步训练所有模型)。对于前者,本文利用 LtD 文献中已有的理论保证 [26,23];对于后者,本文提出全新的具有可实现一致性的替代损失(参见定理 2)。
序贯训练(LtA-Seq)
序贯训练将模型学习分为两个步骤:
- 首先训练需要额外人类专家反馈的增强模型g;
- 随后训练标准模型f与选择策略s。
该策略的优势在于,它可利用 LtD 文献中已有的理论保证,将预测器f与选择器s作为一个统一模型进行学习(这与基于分数的 LtD 方法 [20] 的常见做法一致)。事实上,一旦增强模型g固定,即可将其视为 LtD 范式中 “专家预测” 的来源,进而训练委托模型。通过这种方式,可直接利用 LtD 领域已有的理论保障。
联合训练(LtA-Joint)
另一种方案是对三个模型进行联合训练。然而,现有 LtD 方法并未考虑 “专家(此处指增强模型g)与委托模型联合训练” 的场景。借鉴 “选择器 – 预测器框架”[20] 的思路,本文采用替代损失ℓs学习式(6)中的选择器,最终得到如下损失函数:
L~ask(f~(x),g~(x,h),s~(x),y)=ℓf(f~y(x),y)ℓs(−s~(x))+ℓg(g~y(x,h),y)ℓs(s~(x))(10)
其中:
- f~y(x):X→R表示标准模型f对应类别y的对数几率(logit);
- g~y(x,h):X×H→R表示增强模型g对应类别y的对数几率;
- s~(x):X→R+表示选择函数对应的对数几率,满足s(x)=I{s~(x)>0}(即当s~(x)>0时,选择增强模型)。
在对替代损失ℓf、ℓg和ℓs施加一定假设的前提下,本文证明式(10)中的替代损失L~ask具有F×G×S- 可实现一致性,具体如以下定理所示:
定理 2
假设F、G和S对缩放操作封闭,并考虑满足以下条件的替代损失:
- (a)ℓf=ℓg=ℓsurr为 “组合和损失”(comp-sum loss)[21],即ℓsurr:[0,1]×Y→[0,1],且对于固定的y,ℓsurr关于第一个参数非递增,同时满足ℓsurr(32,y)>0且limv→1ℓsurr(v,y)=0;
- (b)ℓs为基于边际的单调损失,满足limv→∞ℓs(v)=1、limv→−∞ℓs(v)=0,且ℓs(−s~(x))+ℓs(s~(x))=1;
则替代损失L~ask(式 10)关于L0−1ask具有F×G×S- 可实现一致性。
定理 2 解读:若替代损失满足条件(a)和(b),则L~ask是具有F×G×S- 可实现一致性的替代损失。需注意,条件(a)要求ℓsurr的输入空间为[0,1]×Y,在实际应用中,可通过对对数几率取 softmax 轻松满足这一要求 —— 记σyf~(x)=∑y′∈Yexpf~y′(x)expf~y(x)(标准模型的 softmax 输出),σyg~(x,h)=∑y′∈Yexpg~y′(x,h)expg~y(x,h)(增强模型的 softmax 输出)。
在实际应用中,可采用以下损失函数满足定理 2 的要求:对ℓf和ℓg使用平均绝对误差(MAE)损失,对ℓs使用 SIG 损失(sigmoid-based loss):
ℓMAEf(σyf~(x),y)=1−∑y′∈Yexpf~y′(x)expf~y(x)(11)
ℓMAEg(σyg~(x,h),y)=1−∑y′∈Yexpg~y′(x,h)expg~y(x,h)(12)
LSIGs(s~(x))=21(1−tanhs~(x))(13)
显然,上述损失函数均满足定理 2 的要求。
5 实验评估
本节通过合成数据与真实专家数据的模拟决策任务,在不同反馈策略下实证评估 LtA 的有效性。实验旨在回答以下研究问题:
- 问题 1(Q1):LtA 策略与 LtD 在准确率和人类 – 人工智能互补性方面的表现如何?
- 问题 2(Q2):专家反馈类型对性能与互补性的影响程度如何?
- 问题 3(Q3):委托成本δ在缓解欠拟合与平衡性能方面的作用是什么?
数据集与模型
- 合成数据集(Synth):构建多分类任务,包含 4 个特征和 4 个类别,所有特征均具有信息性。为模拟人类专家,使用仅含 2 个特征的决策树训练专家预测器f′(x);机器学习模型则采用仅基于剩余 2 个特征训练的两层感知机。该设置模拟了 “专家掌握机器学习模型无法获取的互补信息” 的场景(与第 3 节的示例一致)。
- NIH 谷歌胸部 X 光数据集(X-Rays):该数据集 [42] 包含约 4400 张匿名胸部 X 光图像及专家标注。每张图像由至少 3 名医生评估 4 种病症(ci):结节 / 肿块、气腔混浊、气胸和骨折。对于每种病症i∈[4],图像被赋予二元真值标签(ci=1表示存在该病症,ci=0表示不存在)。定义整体二元标签Y∈{0,1}:Y=1表示健康(所有ci=0),Y=0表示非健康(至少一个ci=1)。对于每种病症ci,将专家共识pi定义为 “报告该病症的医生比例”,即pi=N1∑j∈Ncij(其中cij为专家j的二元标注,N为标注专家数量)。为模拟专家预测YH,按ci∼伯努利分布(pi)采样病症标签,若所有ci=0则赋值YH=1。该过程反映了专家在判断患者健康状态时的意见差异。机器学习模型采用预训练的深度神经网络 DenseNet [8]。<sup>[5]</sup> 增强模型g同样采用深度神经网络,通过 FiLM 架构 [31](一种成熟的视觉推理方法)注入人类专家反馈。<sup>[5]</sup> 在实际实验中,无论是 LtA 还是 LtD,均按照文献中的标准做法,在 X-Rays 数据集上对 DenseNet 模型进行微调。
专家反馈
定义两种反馈策略:
- LtD-Feedback:h=f′(x)(合成数据集)或h=YH(X-Rays 数据集),模拟专家仅向增强模型提供预测健康标签的场景。
- Unc-Feedback:仅适用于 X-Rays 数据集,h=(p1,p2,p3,p4),模拟专家向增强模型提供每种病症的共识概率(反映专家对病症存在与否的不确定性)。
在 LtD 中,仅考虑 LtD-Feedback(因 LtD 要求专家直接提供预测结果)。
实验设置
对两个数据集均采用 70:10:20 的比例划分训练集、校准集与测试集:
- 训练集:用于训练 LtD、LtA-Seq 和 LtA-Joint 策略下的标准模型与增强模型。
- 对于标准 LtD 和 LtA-Seq:采用 Mozannar 等人 [27] 和 Mao 等人 [22] 提出的可实现一致性损失(该损失在 LtD 中达到当前最优性能)。
- 对于 LtA-Joint:使用式(11)、(12)、(13)分别训练机器模型f、增强模型g与选择器。
- 校准集:按照文献 [27,30] 的标准做法,用于估计不同覆盖率β∈{0.0,…,1.0}下的委托阈值τβ。
- 测试集:用于计算各方法在不同阈值下的实证准确率。
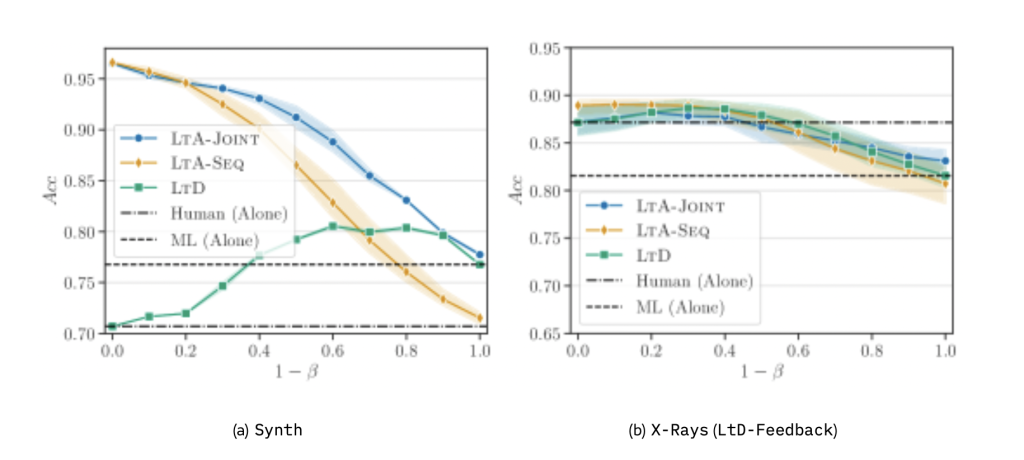
为评估互补性(即人类 – 机器团队是否优于单独的人类或机器 [36]),还需测量(模拟)专家与单独模型的准确率。实验重复 5 次,每次均重新采样训练集、校准集与测试集。更多细节详见附录 B。
(a)合成数据集(Synth)的结果;(b)X-Rays 数据集采用 LtD-Feedback 的结果;(c)X-Rays 数据集采用 Unc-Feedback 的结果。图(c)中同样包含 LtD 基线模型。虚线分别表示专家单独预测与机器单独预测的实证准确率。阴影区域表示 5 次实验的标准差。
5.1 实验结果
问题 1:LtA-Joint 和 LtA-Seq 的性能优于传统 LtD,且 LtA-Seq 对欠拟合较为敏感
首先在合成分类任务(Synth)上比较 LtA-Seq、LtA-Joint 与标准 LtD 的性能。结果表明,允许获取更多人类反馈使 LtA 具有明显优势:当1−β<.50(即专家查询预算较高)时,LtA-Seq 和 LtA-Joint 均显著优于 LtD;其中,LtA-Joint 在所有覆盖率下均持续优于 LtD,而 LtA-Seq 在1−β≥.70(即专家查询预算较低)时准确率低于 LtD。此外,通过更有效地利用反馈,LtA 的互补性强于 LtD,其准确率超过了单独的模拟专家与单独的机器预测。
LtA-Seq 与 LtA-Joint 在高覆盖率下的性能差距可归因于二者的训练流程:如第 4.1 节所述,LtA-Seq 先训练增强模型g,且训练过程中未对专家查询施加惩罚(δ=0)。在1−β=0(完全依赖专家)时,g的准确率比模拟专家高约 20%,这导致 LtA-Seq 过度依赖g,进而引发其他模型头(如标准模型f)的欠拟合 —— 这是 LtD 中已知的问题 [18]。
然而,图 4 表明,只需增加委托成本,即可在真实专家数据上缓解这一问题,使 LtA-Seq 的性能接近 LtA-Joint。相比之下,LtA-Joint 通过联合训练自然避免了过度依赖:其联合训练过程起到了正则化作用,仅在有益时才利用专家反馈,从而限制了专家查询的频率。
问题 2:在真实数据上,当反馈形式为硬预测时,LtA 与 LtD 性能相当;当反馈形式更丰富时,LtA 性能显著提升
在 X-Rays 数据集上评估不同反馈策略(LtD-Feedback 与 Unc-Feedback)的影响:
- LtD-Feedback(硬预测):LtA-Joint 与 LtA-Seq 的性能与 LtD 基本持平,整体互补性有限,所有方法的准确率仅略高于单独专家的预测(图 3(b))。
- Unc-Feedback(不确定性反馈):LtA 展现出明显优势 ——LtA-Seq 与 LtA-Joint 均优于 LtD,在1−β=.10时准确率提升约 5%(图 3(c))。通过利用更丰富的反馈,LtA 的互补性显著增强:当1−β≤.05时,其准确率超过了单独专家与单独机器的预测。
与预期一致,采用 Unc-Feedback 时,LtA-Seq 在1−β≥.50时仍存在欠拟合问题 —— 这是因为与硬预测相比,不确定性反馈的复杂度更高,进一步加剧了 LtA-Seq 的过度依赖倾向。
问题 3:增加委托成本可减少 LtA-Seq 的欠拟合,使其性能向 LtA-Joint 靠拢
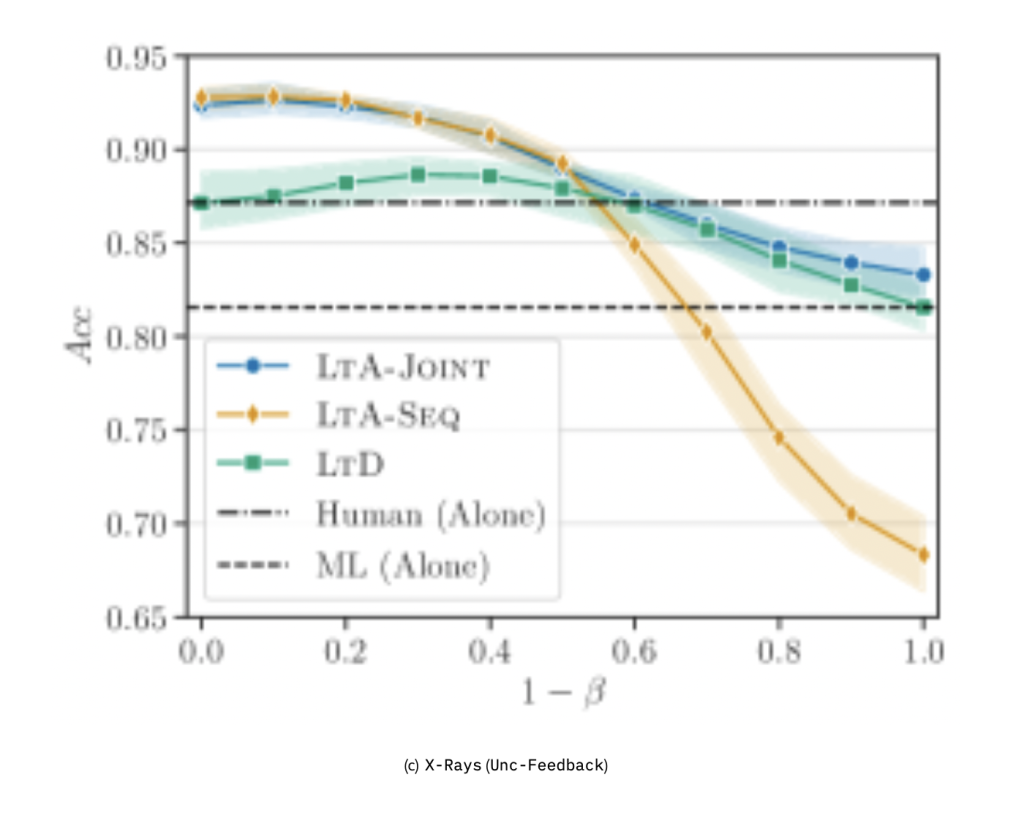
最后,研究训练过程中委托成本δ对缓解传统 LtD 欠拟合问题 [27,18] 的作用。图 4 报告了 X-Rays 分类任务中,不同δ值对各方法性能的影响:
- LtD:引入委托成本在高覆盖率下仅带来小幅提升 —— 当1−β∈{.80,.90}时,设置δ=0.2可使准确率提升约 3%(图 4(a))。
- LtA-Seq:委托成本的影响更为显著(图 4(b))—— 当1−β>.50时,准确率大幅提升;当δ=0.2且1−β=.90时,准确率最高提升约 16%。这表明,引入委托成本能有效减少对专家组件的过度依赖,缓解欠拟合问题。
- LtA-Joint:增加δ会略微降低性能(图 4(c))。原因在于,对专家反馈施加惩罚会增加联合策略优化增强模型的难度。
综上,尽管委托成本对 LtD 的提升有限(且 LtD 在反馈丰富时性能仍低于 LtA),但对 LtA-Seq 而言,合适的委托成本可使其性能接近 LtA-Joint,进一步验证了 LtA 的有效性。
(a)LtD 在不同δ下的结果;(b)、(c)分别为 LtA-Seq 和 LtA-Joint 在采用不确定性反馈时的结果。阴影区域表示 5 次实验的标准差。
6 结论
本文提出 “学习询问”(LtA)这一全新的人类 – 人工智能协作框架。与 “学习委托”(LtD)仅关注 “将决策委托给人类” 不同,LtA 致力于学习 “何时查询人类专家反馈” 并将其融入预测过程。
本文的核心贡献包括:
- 证明存在数据分布使得 LtD 具有次优性;
- 推导了包含专家查询预算约束的最优选择策略;
- 提出两种实用的训练方法 —— 序贯训练与联合训练(后者采用全新的具有可实现一致性的替代损失);
- 实证表明,LtA 在性能上始终持平或优于 LtD,且在融入多样化专家反馈方面具有更高的灵活性。
局限性与未来研究方向
本文仍存在一些局限性,为未来研究提供了方向:
- 理论分析深化:部分理论问题仍未解决,例如如何设计具有F×G×S- 一致性界的替代损失。尽管定理 2 刻画了 LtA 的F×G×S- 可实现一致性替代损失,但本文仅证明 “最小化替代损失可找到最优(f,g,s)∗∈F×G×S”,尚未涉及贝叶斯一致性。这一局限凸显了更精细分析的必要性,例如探索Q- 一致性界 [23]。
- 反馈类型优化:当前框架依赖固定的查询结构,而实际应用中可能需要根据样本调整查询形式(从简单预测到丰富标注,如不确定性估计、结构化解释等)。未来研究可聚焦于 “不仅决定是否委托,还能决定查询内容” 的机制,以更高效地利用人类专业知识。
致谢
本研究部分得到以下项目支持:
- 欧盟 “地平线欧洲计划”(Horizon Europe Programme),资助编号 #101120237(ELIAS 项目)和 #101120763(TANGO 项目)。本研究成果仅代表作者观点,不代表欧盟或欧洲卫生与数字执行局(HaDEA)的立场,欧盟及资助机构不对其承担任何责任。
- 意大利企业与 “意大利制造” 部(Ministero delle Imprese e del Made in Italy),IPCEI Cloud DM 项目(2022 年 6 月 27 日,编号 IPCEI-CL-0000007)。
- 意大利国家复苏与韧性计划(PNRR)M4C2 投资 1.3 项,扩展合作伙伴项目 PE00000013(“FAIR – 未来人工智能研究”),由欧盟 “下一代欧盟” 计划资助。
- SoBigData.it 项目,由欧盟 “下一代欧盟” 计划下的意大利国家复苏与韧性计划(PNRR)资助,项目编号 IR0000013(2021 年 12 月 28 日第 3264 号通知),旨在加强意大利社会挖掘与大数据分析领域的研究基础设施。
参考文献(略,与原文一致)
附录 A 证明过程
A.1 示例的完整推导
本节提供 “学习委托”(LtD)次优性示例的完整推导。
首先,分析 LtD 系统的期望准确率。给定固定样本x=(x1,x2),可将期望分解为 “人类专家的期望准确率” 与 “机器的期望准确率” 两部分:Acc(f,f′,s(x1))=Ey[s(x1)I{f(x1)=y}+(1−s(x1))I{f′(x2)=y}]=y∈Y∑P(Y=y∣x1,x2)[s(x1)I{f(x1)=y}+(1−s(x1))I{f′(x2)=y}]=s(x1)y∈Y∑P(Y=y∣x1,x2)I{f(x1)=y}+(1−s(x1))y∈Y∑P(Y=y∣x1,x2)I{f′(x2)=y}=s(x1)Ey[I{f(x1)=y}]+(1−s(x1))Ey[I{f′(x2)=y}]
接下来,分别分析这两个期望。在本示例中,若同时观测x1和x2,可确定性地确定正确标签,因此对任意(y,x1,x2)组合,均有P(Y=y∣x1,x2)=1(其他组合为 0)。合成分类任务的完整数据分布如表 1 所示。
表 1:合成分类任务中,不同特征组合x=(x1,x2)对应的标签概率分布(第 3 节描述)
| x1 | x2 | P(Y=y∣x1,x2) | |||
|---|---|---|---|---|---|
| y=0 | y=1 | y=2 | y=3 | ||
| 0 | 0 | 1 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 0 | 0 |
| 1 | 0 | 0 | 0 | 1 | 0 |
| 1 | 1 | 0 | 0 | 0 | 1 |
因此,给定固定样本x,人类专家与机器的期望准确率可表示为:Ey[I{f(x1)=y}]=y∈Y∑P(Y=y∣x1,x2)P(f(x1)=y∣x1)=0⋅0+0⋅0+0⋅21+1⋅21=21
由于s(x1)∈(0,1),LtD 系统的整体期望准确率Acc(f,f′,s(x1))始终为21。
若不采用 “委托给人类专家” 的模式,而是使用贝叶斯最优增强预测器(融合机器信号与专家提供的特征x2),则准确率会显著提高:Ey[I{g(x1,x2)=y}]=y∈Y∑P(Y=y∣x1,x2)P(g(x1,x2)=y∣x1,x2)=0⋅0+0⋅0+0⋅0+1⋅1=1
事实上,只要s(x1)>0,增强系统的准确率就满足:
s(x1)Ey,f[I{f(x1)=y}]+(1−s(x1))Ey,f′[I{g(x1,x2)=y}]=s(x1)21+(1−s(x1))1≥21
A.2 图 2 的实验设置
构建合成分类任务:包含 4 个类别Y∈{0,1,2,3},每个类别由一对二元潜在特征(b1,b2)∈{0,1}2定义。每个类别映射到两个观测特征(x1,x2),其中心位于(±sep,±sep),并加入高斯噪声扰动。
为控制特征信息性,可选择性地沿x1轴(机器特征)或x2轴(专家特征)移动中心:沿x1轴增加分离度会提高机器的准确率,沿x2轴增加分离度则会提高专家的准确率。
生成 4000 个样本,按 60:40 的比例划分为训练集与测试集。分别训练三种逻辑回归模型:
- 仅基于x1(机器预测器f(x1));
- 仅基于x2(专家预测器f′(x2));
- 基于两个特征(增强预测器g(x1,x2))。
评估两种 “最优策略”:
- 学习委托(LtD):动态选择机器或专家的预测结果;
- 学习询问(LtA):优化 “何时查询专家反馈” 的策略(本场景中,专家反馈即专家特征x2)。
最终结果如图 2 所示。
A.3 定理 1 的证明
证明:
首先考虑无约束情况,即最小化以下目标函数:
s∈SminE(x,y,h)[(1−s(x))ℓf(f(x),y)+s(x)ℓg(g(x,h),y)](14)
将目标函数重写为:E(x,y,h)[(1−s(x))ℓf(f(x),y)+s(x)ℓg(g(x,h),y)]=Ex[(1−s(x))Ey∣x[ℓf(f(x),y)]+s(x)Ey,h∣x[ℓg(g(x,h),y)]]=Ex[Ey∣x[ℓf(f(x),y)]]+Ex[s(x)(Ey,h∣x[ℓg(g(x,h),y)]−Ey∣x[ℓf(f(x),y)])]
由于第一项与s无关,优化问题可简化为:
s∈[0,1]∀x∈XminEx[s(x)(Ey,h∣x[ℓg(g(x,h),y)]−Ey∣x[ℓf(f(x),y)])](15)
这是一个关于x的可分离线性优化问题,因此对任意x∈X,最优选择器为:
s∗(x)={1若Ey∣x[ℓf(f(x),y)]−Ey,h∣x[ℓg(g(x,h),y)]>00其他情况(16)
接下来考虑带预算约束的情况,即优化问题变为:s∈[0,1]∀x∈Xmins.t.E(x,h,y)[(1−s(x))ℓf(f(x),y)+s(x)ℓg(g(x,h),y)]EX[s(x)]≤β(17)
构建对偶问题:λ≥0maxs∈[0,1]∀x∈XminE(x,h,y)[(1−s(x))ℓf+λ(s(x)−β)](18)
其中,λ为预算约束的拉格朗日乘子。与无约束情况类似,内层优化的最优选择器为:
sλ∗(x)={1若Ey∣x[ℓf]−Ey,h∣x[ℓg]>λ0其他情况(19)
注意到:Ex[sλ∗(x)]=Ex[I{Ey∣xℓf−Ey,h∣xℓg>λ}]=Px(Ey∣xℓf−Ey,h∣xℓg>λ)=1−Px(Ey∣xℓf−Ey,h∣xℓg≤λ)
在最优解λ∗处,约束条件Ex[s(x)]≤β取等号,即λ∗满足:
Px(Ey∣xℓf−Ey,h∣xℓg≤λ∗)=1−β
由连续性假设可知,λ∗是 “期望差值Ey∣xℓf−Ey,h∣xℓg” 的(1−β)分位数。
证毕。
A.4 定理 2 的证明
为证明定理 2,采用与 Mao 等人 [22] 类似的思路:首先证明替代损失上界优于L0−1ask,再证明在可实现性假设下损失收敛至零。
为简化符号,记ℓsurr(v)为 “对数几率的 softmax 值为v时的损失”(即ℓsurr(v)=ℓsurr(v,y))。首先证明,对任意x,h,y及任意f,g,s∈F×G×S,均有:
L0−1ask(f,g,s,y)≤21ℓsurr(32)L~ask(f~,g~,s~,y)(20)
分六种情况讨论:
情况 1:两个预测器均错误(f(x)=y且g(x,h)=y)
此时L0−1ask(⋅)=1。对于L~ask(⋅),有:L~ask=(1−ℓs(s~))ℓsurr(σyf~)+ℓs(s~)ℓsurr(σyg~)≥(1−ℓs(s~))ℓsurr(21)+ℓs(s~)ℓsurr(21)≥(1−ℓs(s~))ℓsurr(32)+ℓs(s~)ℓsurr(32)(21)
其中,第一个等式由假设(b)成立;第一个不等式成立的原因是:若f(x)=y,则σ(f~y)<21(根据贝叶斯法则,预测结果对应最大对数几率),同理σ(g~y)<21;第二个不等式成立的原因是ℓsurr非递增。
两边同时除以正数21ℓsurr(32):21ℓsurr(32)L~ask≥21ℓsurr(32)(1−ℓs(s~))ℓsurr(32)+ℓs(s~)ℓsurr(32)≥ℓsurr(32)(1−ℓs(s~))ℓsurr(32)+ℓs(s~)ℓsurr(32)=1=L0−1ask(22)
其中,第二个不等式成立的原因是ℓsurr(32)>21ℓsurr(32)。
情况 2:两个预测器均正确
此时L0−1ask(⋅)=0,且L~ask(⋅)≥0,因此不等式(20)成立。
情况 3:选择器s(x)=0,f(x)=y且g(x,h)=y
此时L0−1ask(⋅)=1。对于L~ask(⋅),有:L~ask=(1−ℓs(s~))ℓsurr(σyf~)+ℓs(s~)ℓsurr(σyg~)≥21ℓsurr(σyf~)+21ℓsurr(σyg~)≥21ℓsurr(32)+21ℓsurr(σyg~)(23)
其中,第一个不等式成立的原因是:f(x)=y且s(x)=0(即s~<0),因此ℓs(s~)<21;第二个不等式成立的原因是f(x)=y(即σyf~<21)。
两边同时除以21ℓsurr(32):21ℓsurr(32)L~ask≥21ℓsurr(32)21ℓsurr(32)+21ℓsurr(σyg~)≥1+21ℓsurr(32)21ℓsurr(σyg~)≥1=L0−1ask(24)
情况 4:选择器s(x)=1,f(x)=y且g(x,h)=y
此时L0−1ask(⋅)=1,与情况 3 对称,可证明不等式(20)成立。
情况 5:选择器s(x)=1,f(x)=y且g(x,h)=y
此时L0−1ask(⋅)=0,且L~ask(⋅)≥0,不等式(20)成立。
情况 6:选择器s(x)=0,f(x)=y且g(x,h)=y
此时L0−1ask(⋅)=0,且L~ask(⋅)≥0,不等式(20)成立。
综上,六种情况均证明21ℓsurr(32)L~ask(⋅)≥L0−1ask(⋅)。
接下来,假设存在零误差解f∗,g∗,s∗∈F×G×S(即EL0−1ask=0),设f^,g^,s^为替代损失L~ask的最小值点(即f^,g^,s^=argminEL~ask)。则有:EL0−1ask(f^,g^,s^)≤21ℓsurr(32)EL~ask(f^,g^,s^)≤21ℓsurr(32)EL~ask(αf∗,α′g∗,s∗)
其中,第一个不等式由21ℓsurr(32)L~ask≥L0−1ask成立;第二个不等式成立的原因是f^,g^,s^是最小值点,且F、G对缩放封闭。
通过单调收敛定理可证明,当α,α′,γ→∞时,EL~ask(αf∗,α′g∗,γs∗)→0,因此EL0−1ask(f^,g^,s^)=0,即L~ask关于L0−1ask具有F×G×S- 可实现一致性。
证毕。
附录 B 额外实验细节
训练细节
- 合成数据集(Synth):所有方法均训练 150 个 epoch。具体而言:
- LtD:仅训练模型f,共 150 个 epoch;
- LtA-Seq:先训练增强模型g(50 个 epoch),再训练标准模型f(100 个 epoch);
- LtA-Joint:先分别用交叉熵损失预训练f和g(各 50 个 epoch),再用L~ask联合训练f、g和s(100 个 epoch)。
- X-Rays 数据集(两种反馈策略):所有方法均训练 300 个 epoch。具体而言:
- LtD:仅训练模型f,共 300 个 epoch;
- LtA-Seq:先训练增强模型g(200 个 epoch),再训练标准模型f(100 个 epoch);
- LtA-Joint:先分别用交叉熵损失预训练f和g(各 200 个 epoch),再用L~ask联合训练f、g和s(100 个 epoch)。
两个数据集均采用随机梯度下降(SGD)优化器,初始学习率设为 0.001。LtA-Joint 的独立预训练阶段可避免 “仅训练f或仅训练g” 的训练崩溃问题。
硬件与训练时间
实验使用 224 核机器,配置如下:
- CPU:Intel(R) Xeon(R) Platinum 8480CL;
- GPU:8 块 NVIDIA H100 80GB HBM3;
- 操作系统:Ubuntu 22.04.3 LTS。
训练时间统计(平均值 ± 标准差):
- 合成数据集:
- LtD:≈40±0.60 秒;
- LtA-Seq:≈48±0.37 秒;
- LtA-Joint:≈75±3 秒。
- X-Rays 数据集(Unc-Feedback):
- LtD:≈4860±50 秒;
- LtA-Seq:≈5010±289 秒;
- LtA-Joint:≈5956±130 秒。
- X-Rays 数据集(LtD-Feedback):
- LtD:≈4860±50 秒;
- LtA-Seq:≈5967±298 秒;
- LtA-Joint:≈6602±207 秒。
文章来源: