开源党狂喜!DeepSeek-OCR 魔搭实操教程,低显存也能实现高吞吐文本解析
1.前言
DeepSeek‑OCR 是由 DeepSeek AI 团队推出的开源视觉‑语言模型,核心目标是通过“光学压缩”把长文本转化为图像,再将图像压缩为少量视觉 token,实现对超长文本的高效 OCR 与上下文理解。

DeepSeek‑OCR 通过将文本转化为视觉信息并进行高效压缩,突破了传统 OCR 在长文本、复杂布局和多语言场景下的瓶颈。其核心技术(光学压缩 + MoE 解码)使得模型在保持 97% 以上精度的同时,实现 10‑20 倍的 token 压缩,具备低显存、高吞吐、开源易用等优势,已成为大模型长上下文处理和多模态文档解析的前沿方案。
这2天DeepSeek‑OCR 非常火爆,今天我们在魔搭社区是手把手教大家部署这个模型,体验和感受一下这个模型的能力。
2.模型部署实战
2025年10月21日国内的魔搭社区已经上架了这块模型(DeepSeek‑OCR),我们登录魔搭社区平台查看这个模型

我们查看一下权重文件
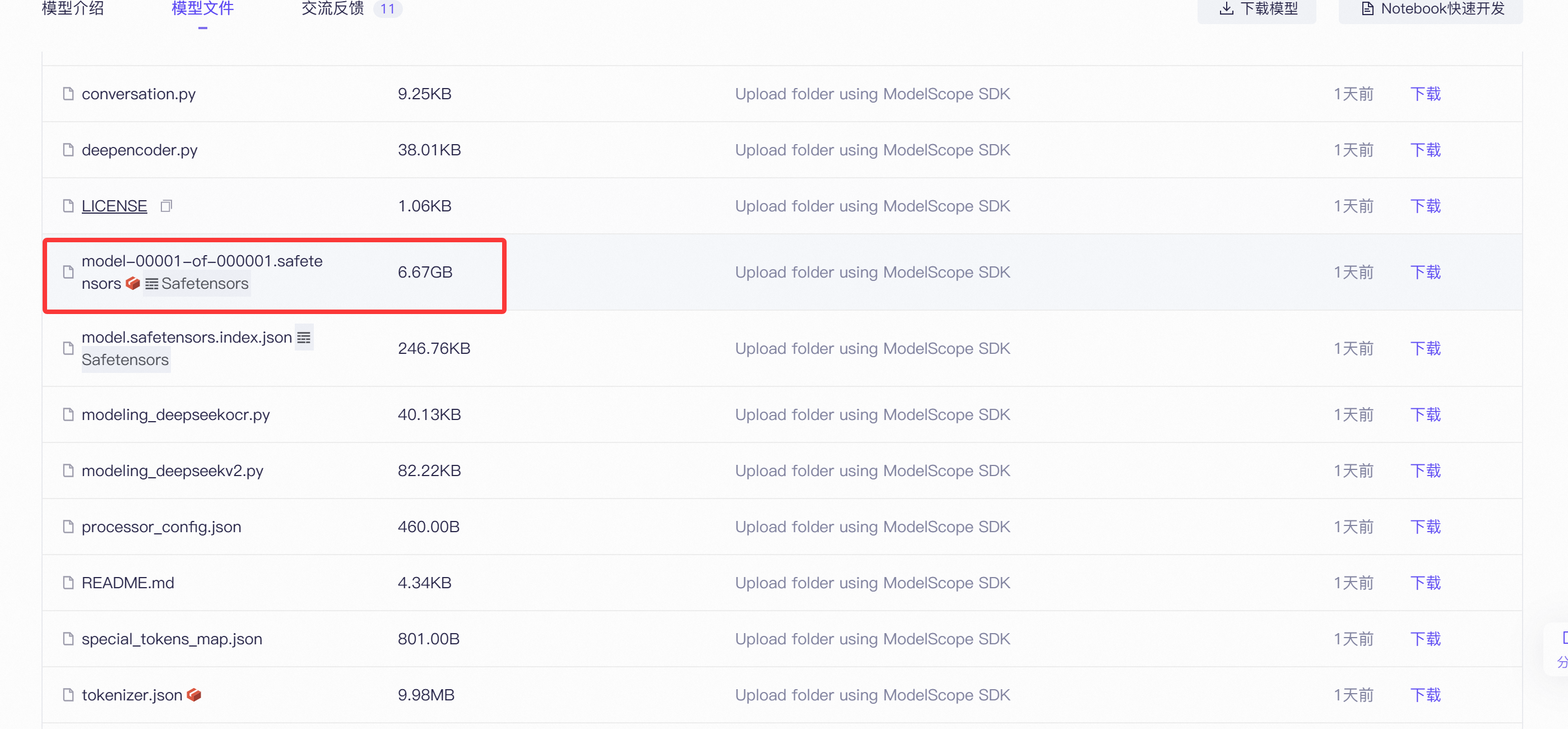
这个模型权重文件大概 6.67GB,这样的我们在消费机显卡上也能实现模型的推理。
模型下载
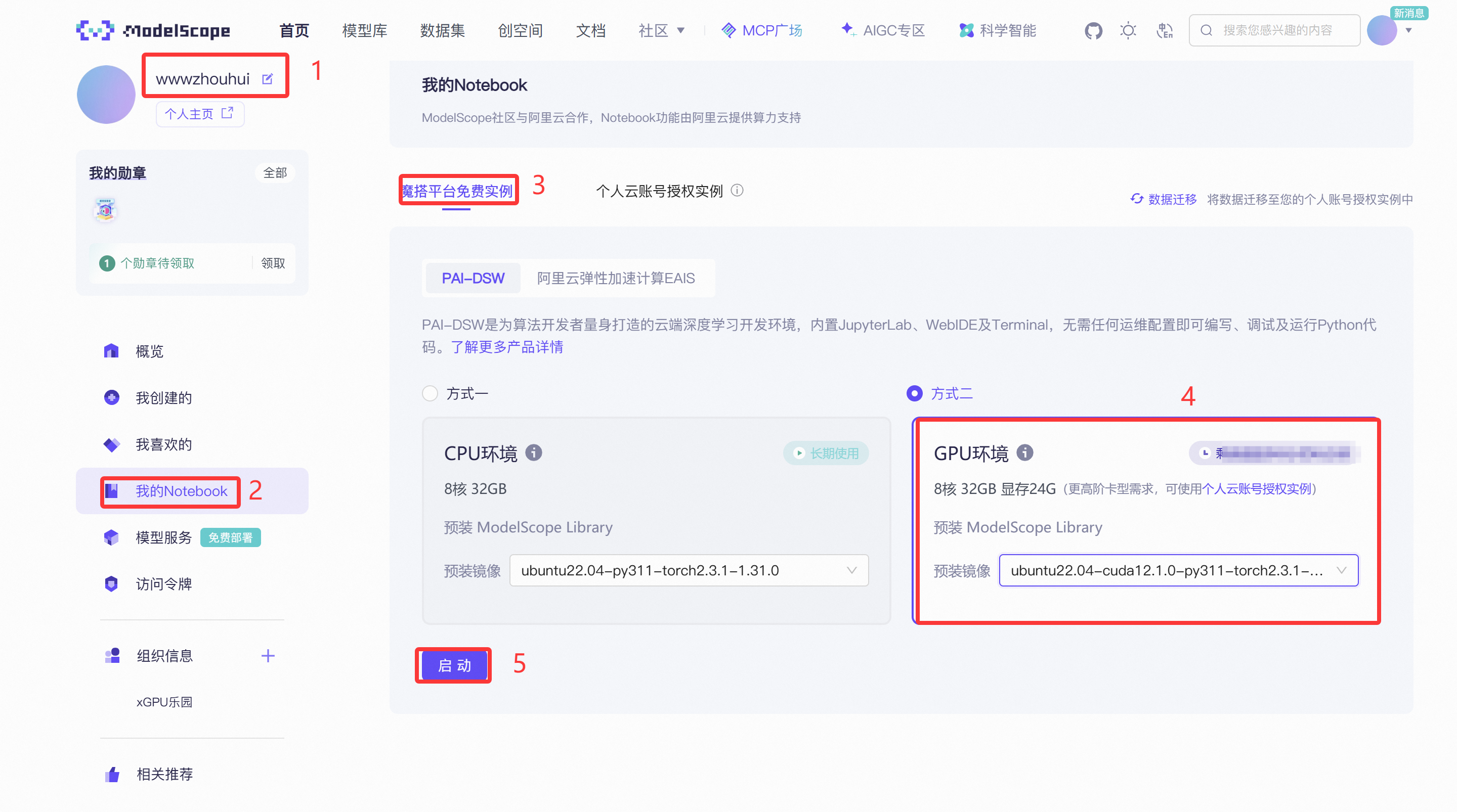
我们首先需要在魔搭社区提供的nodebook 开启带有GPU的服务。
在我的个人主页里面,我的nodebook——魔搭平台免费实例——GPU环境,模型镜像就选择最新的ubuntu22.04-cuda12.1.0-py311-torch2.3.1-tf2.16.1-1.31.0
启动完成后我们大概等待几分钟后,后端服务给我们分配服务器,分配好后我们看到下面的画面
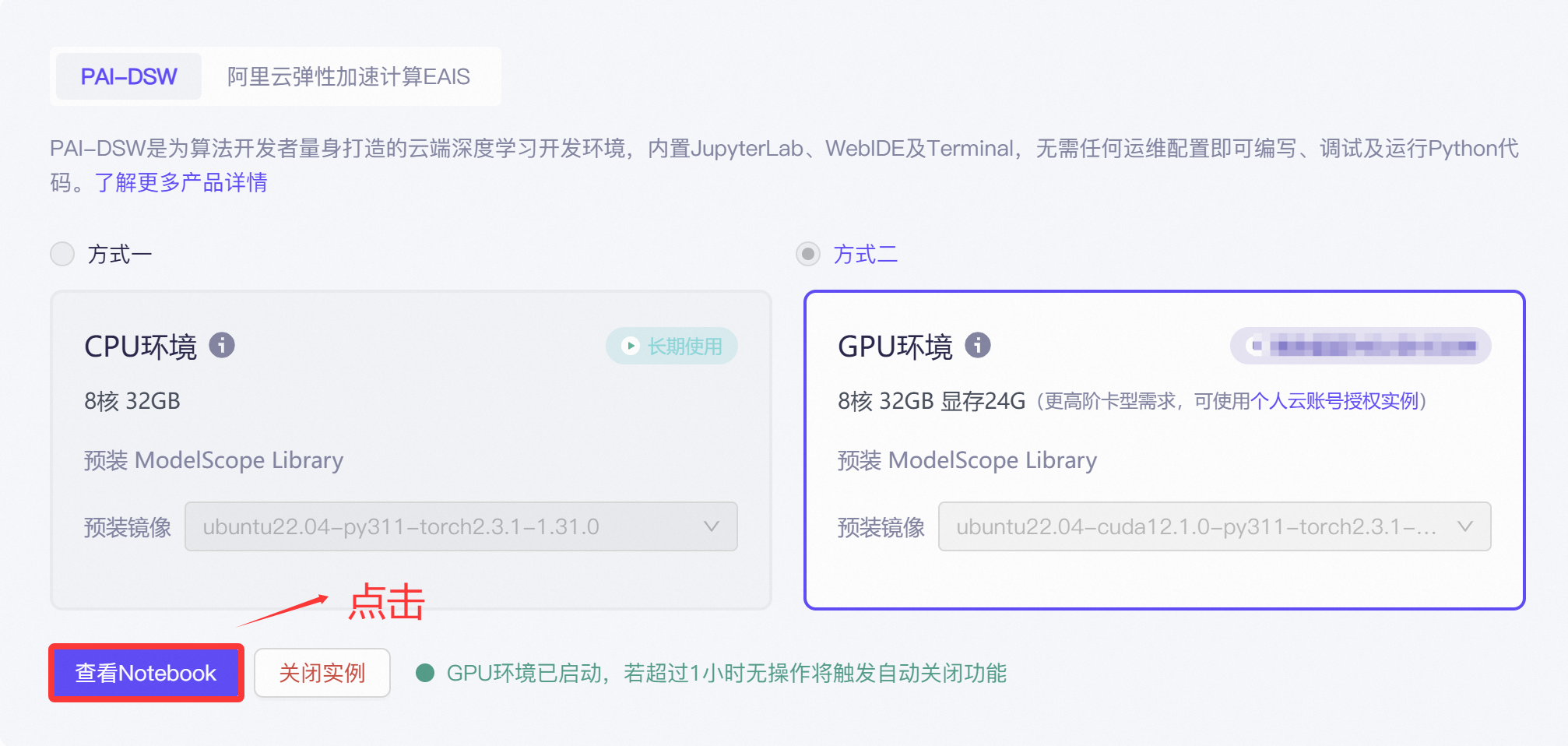
我们点击查看notebook 进入 jupyter 调试页面 (每天第一次登录 后会调转到阿里云授权,手机扫描授权即可)
我之前的notebook 空间里面有之前安装的东西,如果是新的这里没有那么多文件夹。
打开terminal开启一个终端。我们输入下面命令行下载模型
css体验AI代码助手代码解读复制代码modelscope download --model deepseek-ai/DeepSeek-OCR --local_dir /mnt/workspace/models
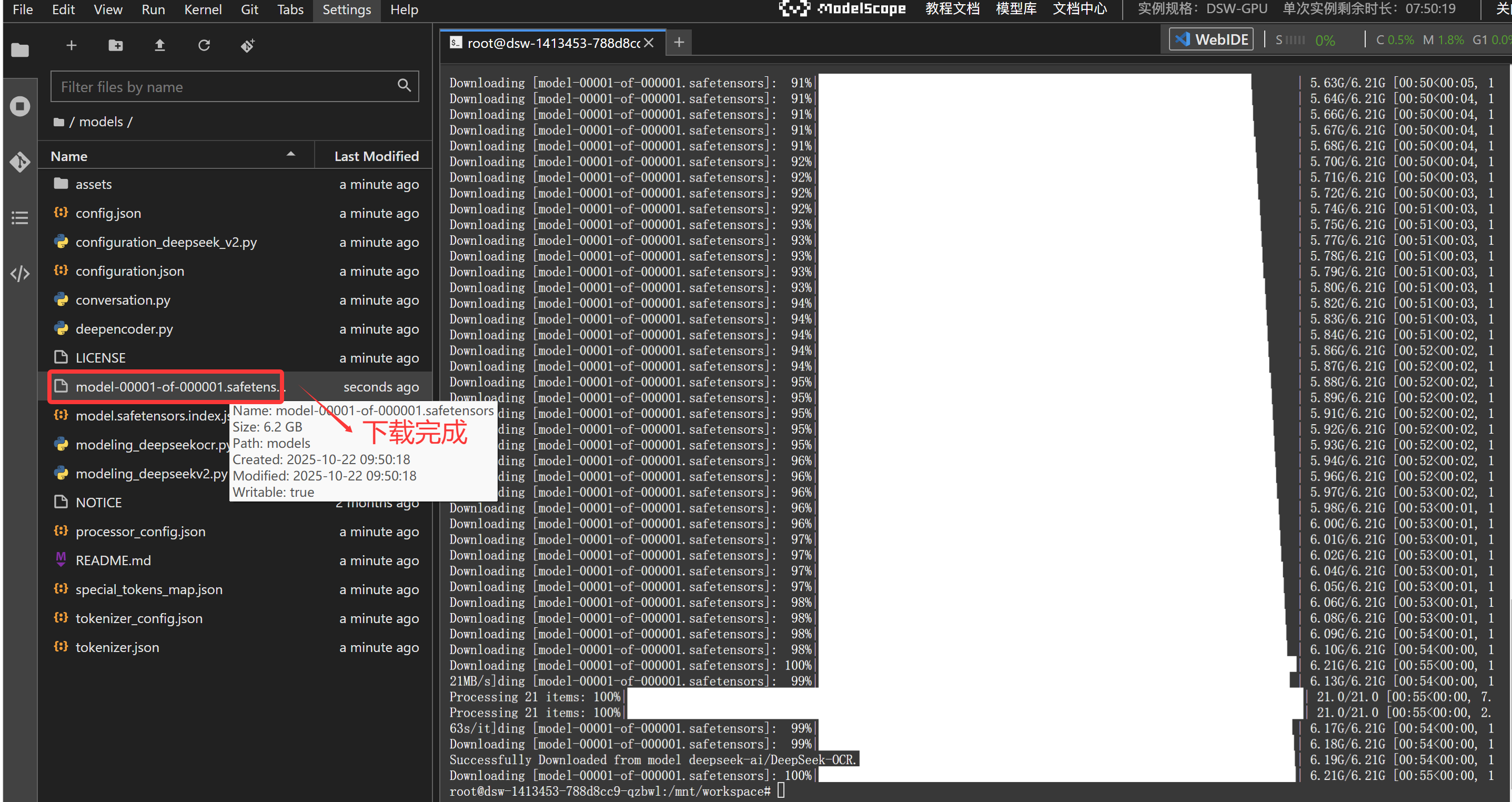
我们大概等待几分钟后就看到下载好的模型文件了。
依赖安装
官方测试环境是测试环境为python 3.12.9 + CUDA11.8
ini体验AI代码助手代码解读复制代码torch==2.6.0
transformers==4.46.3
tokenizers==0.20.3
einops
addict
easydict
pip install flash-attn==2.7.3 --no-build-isolation
魔搭提供的镜像ubuntu22.04-cuda12.1.0-py311-torch2.3.1-tf2.16.1-1.31.0版本 我们需要安装一下依赖包
ini体验AI代码助手代码解读复制代码pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
pip install vllm==0.8.5
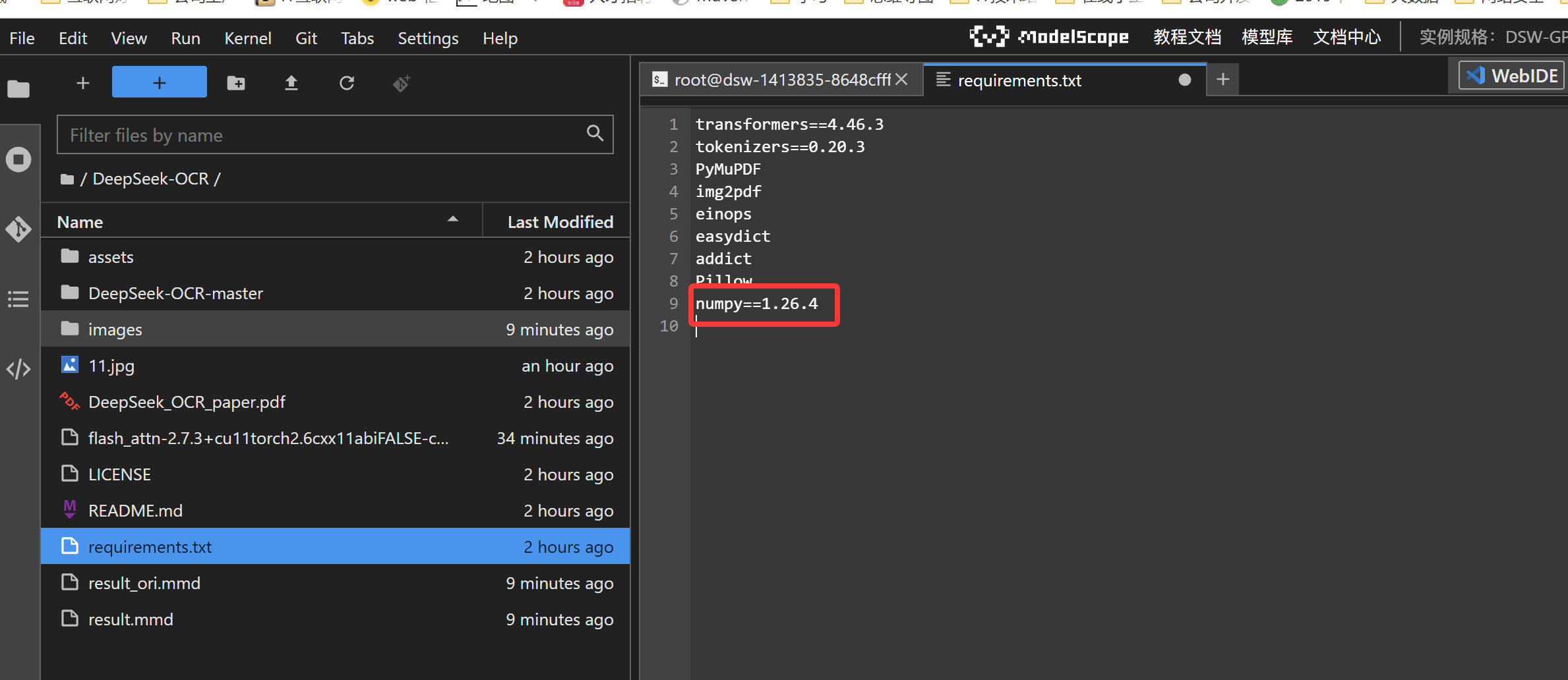
这里我们还需要修改requirements.txt里面的numpy==1.26.4( 不修改会报错)
另外我们还需要下载flash-attn==2.7.3 这个版本,这里我们需要通过下载离线包上传并安装
下载完成后我们需要把这个离线包上传魔搭社区notebook调试环境中
上传后我们通过下面命令安装flash-attn==2.7.3
bash体验AI代码助手代码解读复制代码cd /mnt/workspace/DeepSeek-OCR
pip install flash_attn-2.7.3+cu11torch2.6cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
安装完成后我们检查这个依赖
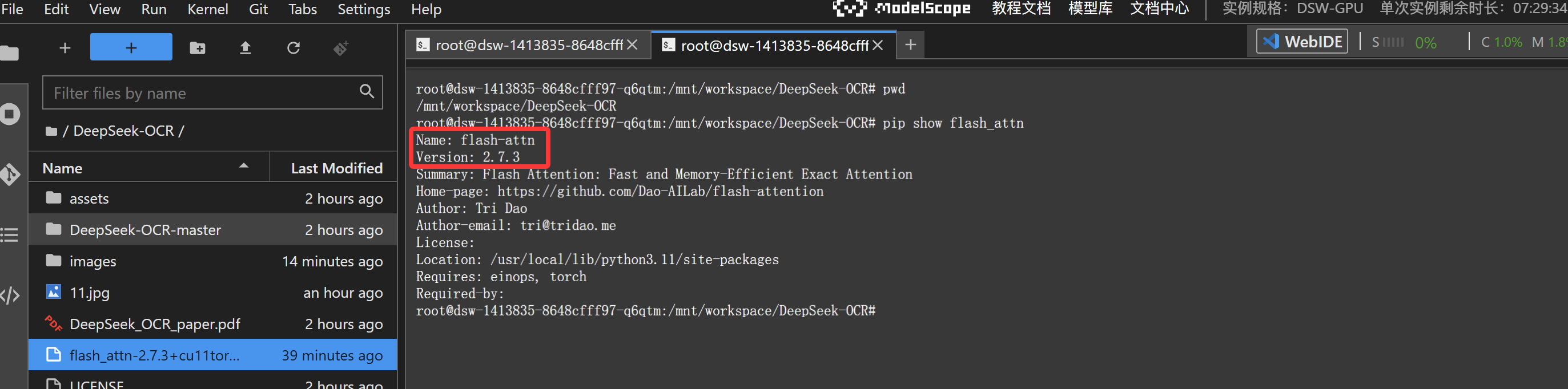
模型推理
我们在github上找到官方的推理代码github.com/deepseek-ai…
默认的官方推理代码比较简单
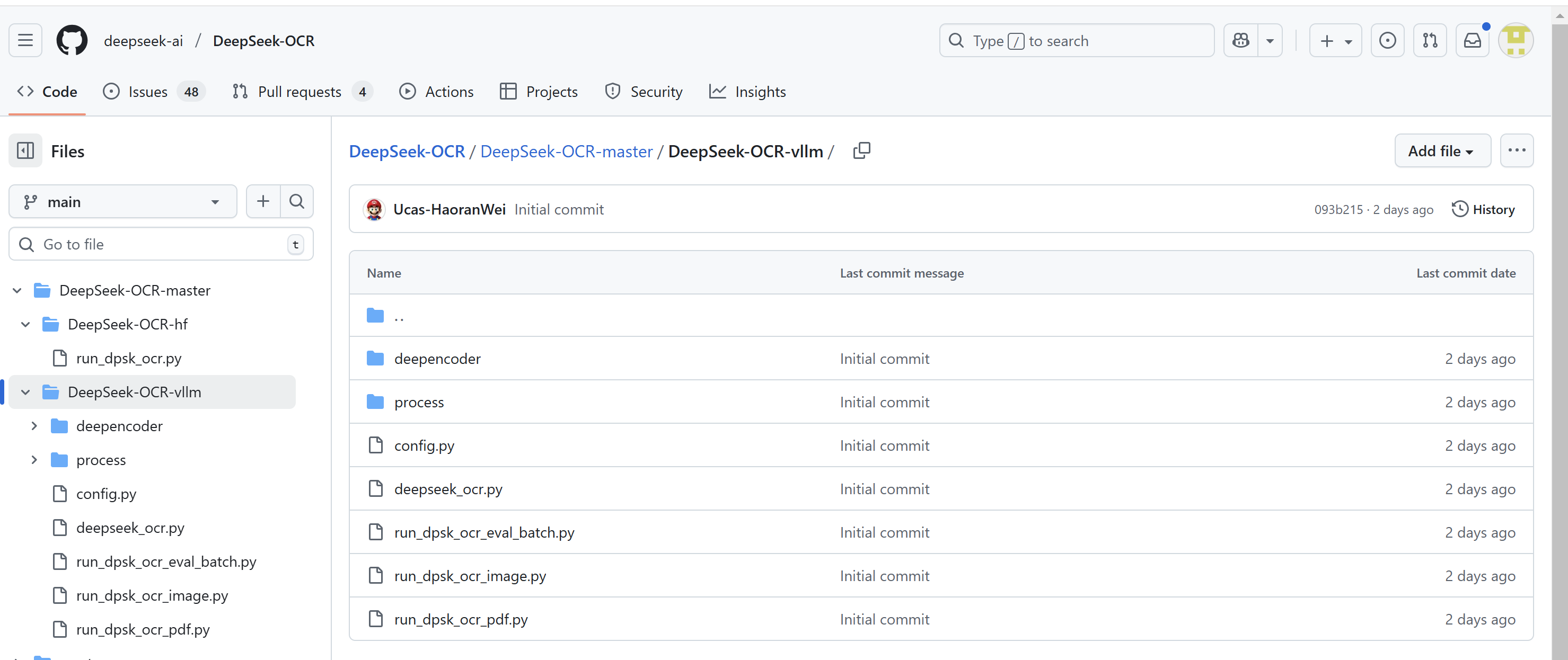
我们现在官方的推理代码
bash体验AI代码助手代码解读复制代码cd /mnt/workspace
git clone https://github.com/deepseek-ai/DeepSeek-OCR
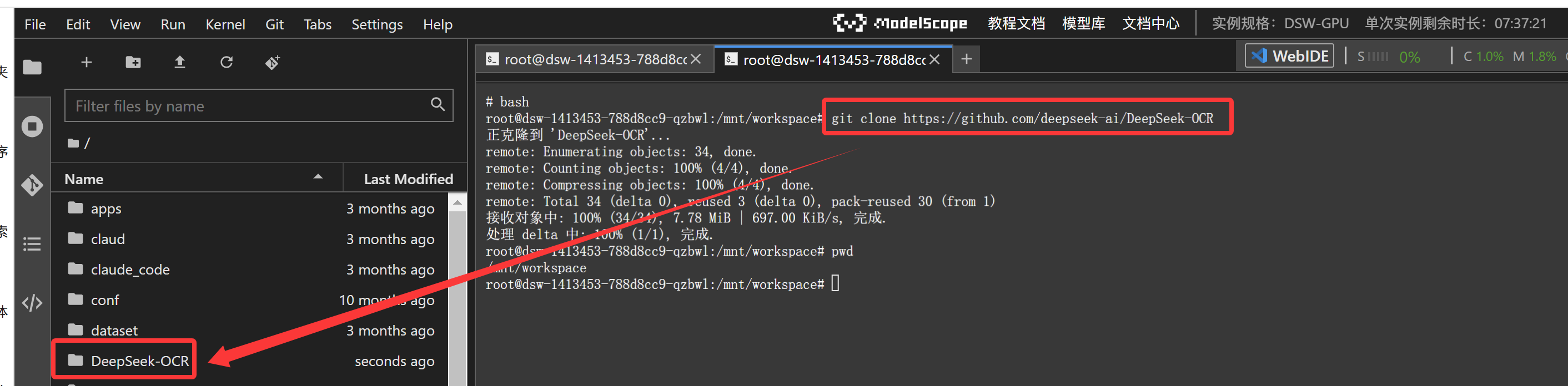
我们需要对推理代码进行修改
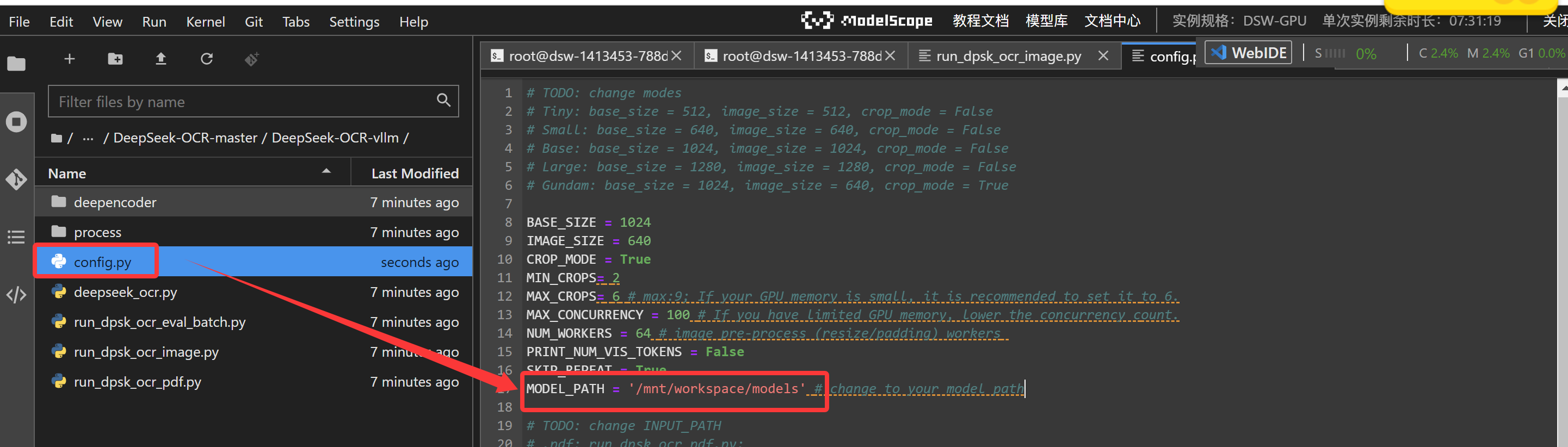
/mnt/workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm 目录下的config.py模型地址修改、输入图片、输出图片路径等信息
ini体验AI代码助手代码解读复制代码MODEL_PATH = '/mnt/workspace/models' # change to your model path
ini体验AI代码助手代码解读复制代码INPUT_PATH = '/mnt/workspace/DeepSeek-OCR/11.jpg'
OUTPUT_PATH = '/mnt/workspace/DeepSeek-OCR'
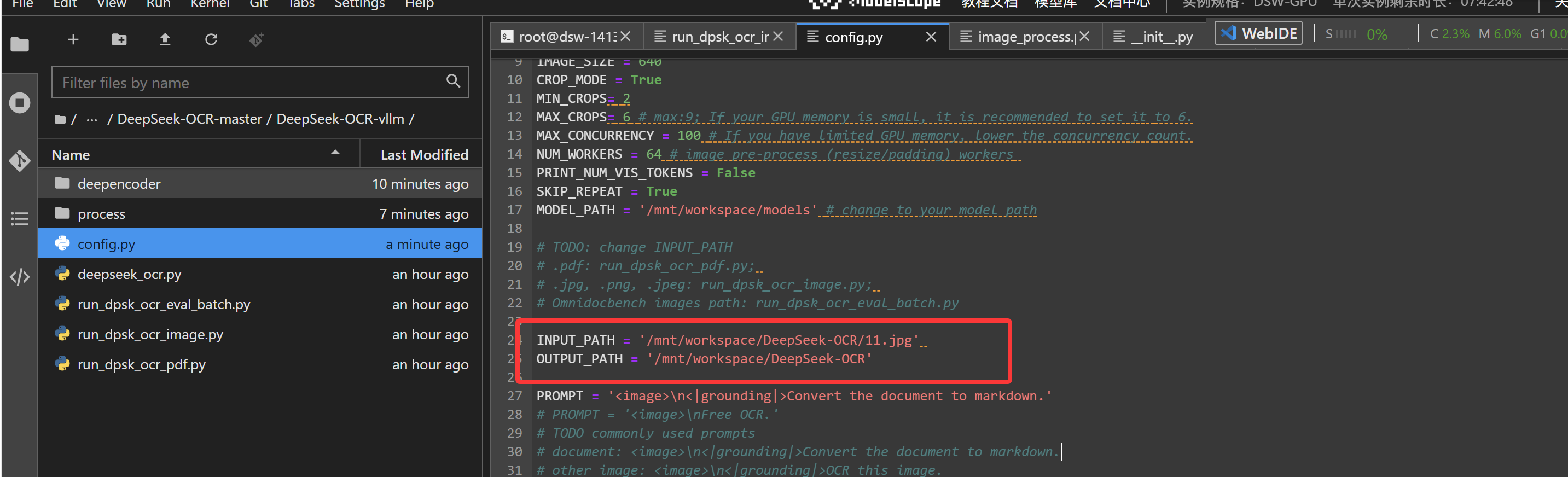
另外我们这里为了测试还需要上传一个11.jpg
接下来我们运行
bash体验AI代码助手代码解读复制代码cd /mnt/workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm
python run_dpsk_ocr_image.py
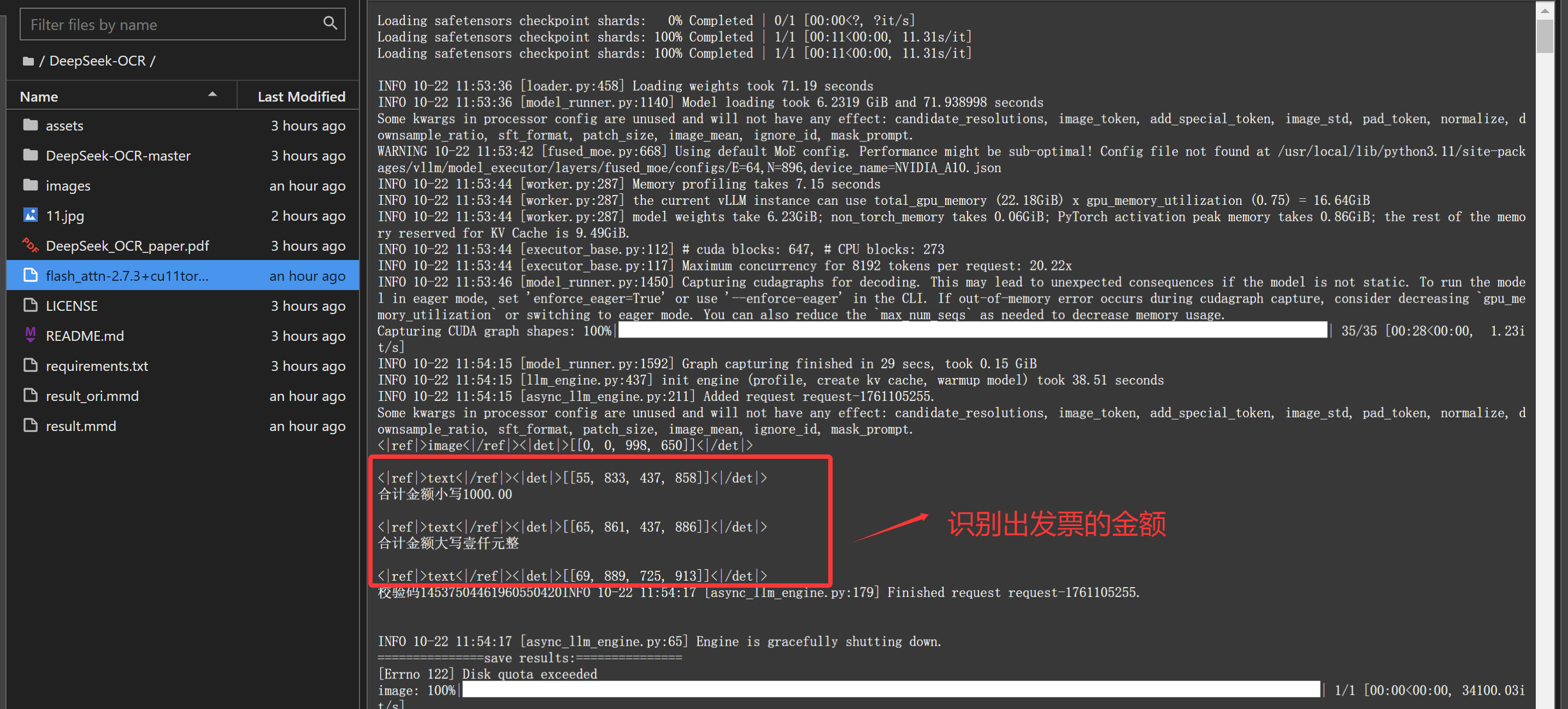 上面的推理都是命令行实现的,目前官方提供的demo确实比较简陋。接下来我们自己编写一个带页面的
上面的推理都是命令行实现的,目前官方提供的demo确实比较简陋。接下来我们自己编写一个带页面的
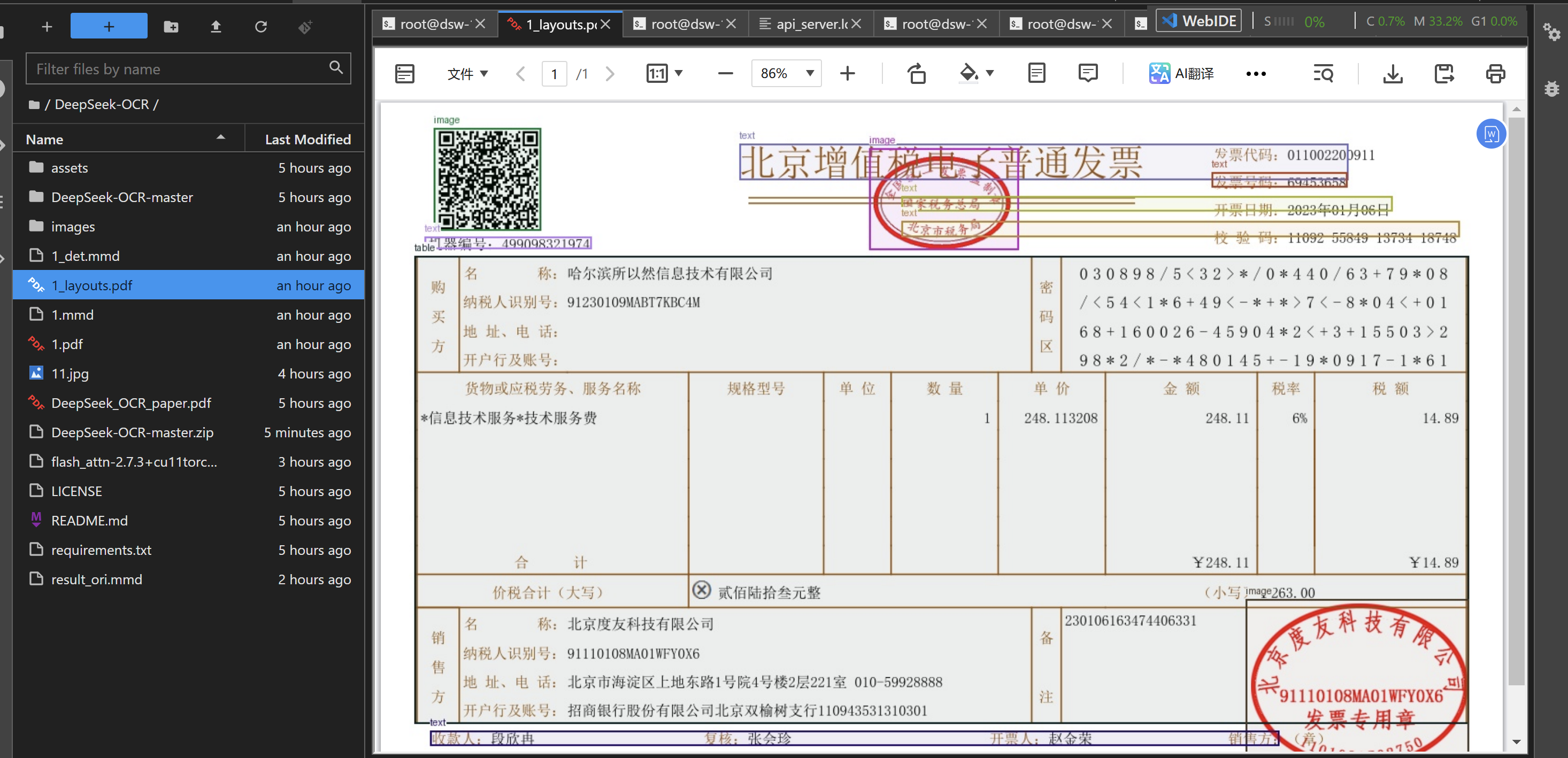
原始票面信息(部分信息我隐掉了)

PDF 标注效果如下:
页面识别的效果如下
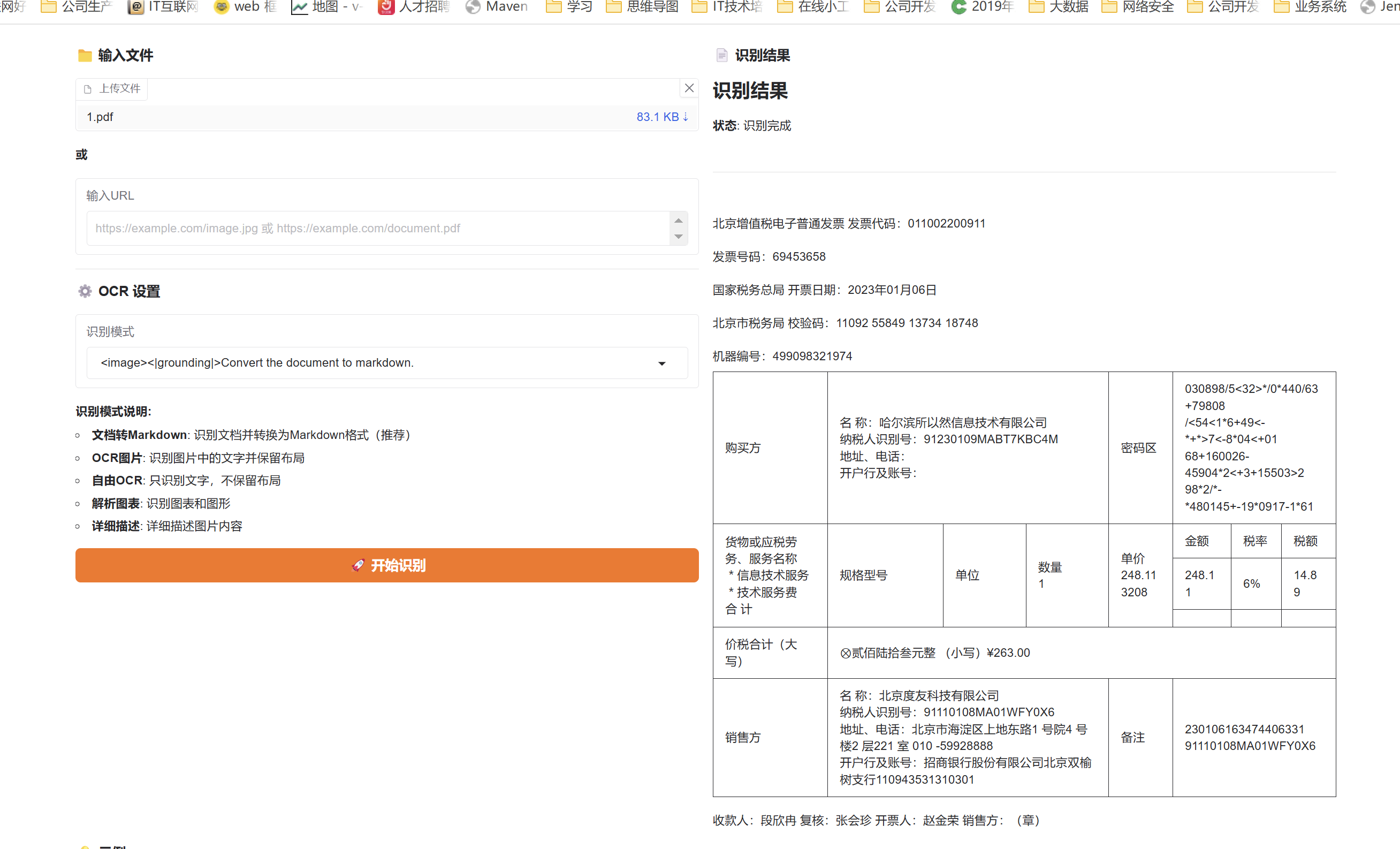
通过对比来看识别率还是挺准的,这张发票基本上识别出来了。
推理的代码有2个一个前端代码 一个是后端代码.代码打包见附件。
通过上面的方式我们轻松在魔搭社区上实现了DeepSeek‑OCR模型的推理。
我们在查看下显存的消耗情况,输入下面的命令
体验AI代码助手代码解读复制代码nvidia-smi
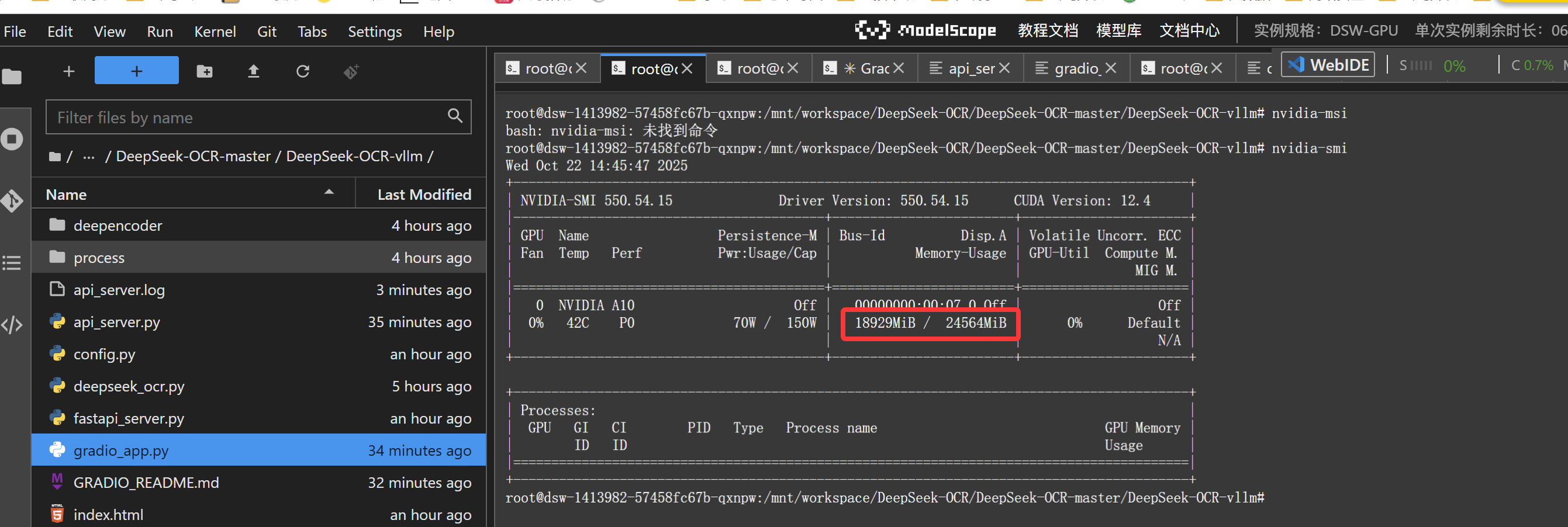
这个显卡大概是24GB显存,目前推理运行起来大概占用到18GB,这里用到VLLM 做推理。有部分是用了显卡的缓存,导致显存占用比较大,实际显存消耗应该小于18GB.基本上家庭消费级显卡是可以运行起来的。
文章来源:https://juejin.cn/post/7563860666349879346